Researching governed memory, verifiable evidence, and AI-assisted discovery.
Lumenais is the umbrella lab. FieldHash is the enterprise product front door.
This site preserves the broader research program: companion continuity, governed-memory architecture, synthesis case studies, exploratory bio work, Gnosis adaptation research, and the retired whitepaper archive. Current enterprise governed-memory positioning lives at FieldHash.ai.
Research hub
One lab, several applied systems.
Lumenais Research keeps the full breadth visible: the FieldHash enterprise company, Companion continuity, Deep Synthesis research workflows, Lumenais.Bio explorations, Gnosis governance primitives, and the retired whitepaper lineage.
Commercial spinout
FieldHash, Inc.
The focused enterprise product now lives at FieldHash.ai: governed memory authority and ledger evidence for enterprise AI agents.
FieldHash
Enterprise governed memory and tamper-evident answer-path records, now focused on FieldHash.ai.
Companion
A personal continuity surface for durable memory, reflection, and user-facing state.
Deep Synthesis
Research workflows that keep hypotheses, caveats, null results, and validation plans inspectable.
Research branches
Enterprise product
FieldHash
Governed memory influence and evidence ledgers for agent deployments.
OpenContinuity surface
Lumenais Companion
The personal companion experience built on the governed-memory substrate.
OpenResearch workflows
Deep Synthesis
Long-context synthesis, hypothesis lineage, falsifiability, and validation planning.
OpenExploratory biology
Lumenais.Bio
Bio-oriented synthesis and research lanes, including tau/autophagy work.
OpenGovernance engine
Gnosis
Bounded adaptation, self-audit primitives, and governable state transitions.
OpenRetired archive
Original whitepaper
The broader pre-repositioning technical whitepaper, preserved for lineage and review.
OpenHow it integrates
A governance layer between memory and the model.
Lumenais does not require teams to replace their agent, model, or vector store first. It sits on the answer path: inspect candidate context, enforce approved state, suppress stale or rejected influence, then emit an audit packet your reviewers can inspect.
ACTIVE GATE PIPELINE SIMULATION
1. Dispatch Query
The client application initiates a standard operational check, sending a query to the agent gateway under ordinary VPC or on-prem connectivity.
[Client] Query dispatched: "What is Project Alpha codeword?"
Most AI memory cannot show what governed the answer.
Standard AI can produce a strong answer. Once memory enters the workflow, teams need to know which facts, corrections, and decisions were allowed to steer the next one.
Lumenais preserves what survives review, while stale, rejected, or rolled-back state remains visible for audit without silently becoming a future prior.
Standard workflow
Retrieve, append, repeat.
The next answer depends on whatever context retrieval surfaces unless a human manually carries status, caveats, and prior decisions forward.
Lumenais workflow
Review, govern, verify.
Validated context and contradiction resolutions become inspectable future influence; rejected and rolled-back state stays stored without steering the answer.
Why not just use RAG?
You probably already are — and Lumenais runs on the same retrieval substrate. It is not a better retriever and not a more accurate model: given the same context, answer quality is comparable. What it adds is the part RAG leaves to chance — control over which memory is allowed to influence an answer, and a record of what did.
Influence control
Retrieval surfaces whatever looks similar. Lumenais gates it: approved, current state shapes the answer, while stale, rejected, superseded, or rolled-back state is blocked from live influence.
Auditability
A tamper-evident record of what was approved, rejected, or rolled back — and what actually entered the answer path — so a reviewer can confirm it rather than take it on trust.
Reversibility
Retract a decision and it stops steering future answers. Plain retrieval keeps surfacing a superseded fact because it still looks relevant; governed state does not.
Memory stores facts. Governance controls influence.
The underlying LLM stays frozen during normal use. Learning lives in scoped memory, routing hints, symbolic state, contradiction handling, compression controls, and promotion rules that decide what can shape later answers. Enterprise deployments can configure the layer against customer-approved private, local, VPC, or on-prem models when the work requires tighter data boundaries, with governed-memory events bound to audit artifacts where configured.
Input
A question, document set, dataset, or research session starts the loop.
Retrieve
Candidate memories and prior artifacts surface by reasoning context.
Gate
Scope, evidence, relevance, novelty, and governance checks filter influence.
Answer
The model responds with approved context and current task constraints.
Log
State shifts, caveats, sources, and outcomes become inspectable artifacts.
Promote
Only useful, stable signals become durable context for future sessions.
What governance prevents: rejected brainstorms, stale corrections, and unrelated project notes should remain auditable without becoming hidden priors.
Read the architectureGoverned Memory enables Deep Synthesis.
Standard deep research reports what the sources say. Deep Synthesis uses governed memory to keep hypothesis lineages, caveats, null results, and validation plans inspectable across a research thread. It is an application of the same control plane, not the primary enterprise purchase path.
Hypothesis-first synthesis
New explanations stay linked to evidence, caveats, confounders, and source context.
Null-result aware
Weakened paths are not re-promoted unless the changed discriminator is explicit.
Validation-routable
Strong ideas are paired with controls, readouts, and explicit failure conditions.
Research Lab inside
The validation lane runs tournaments, preserves negative results, and returns interpretable structure when supported.
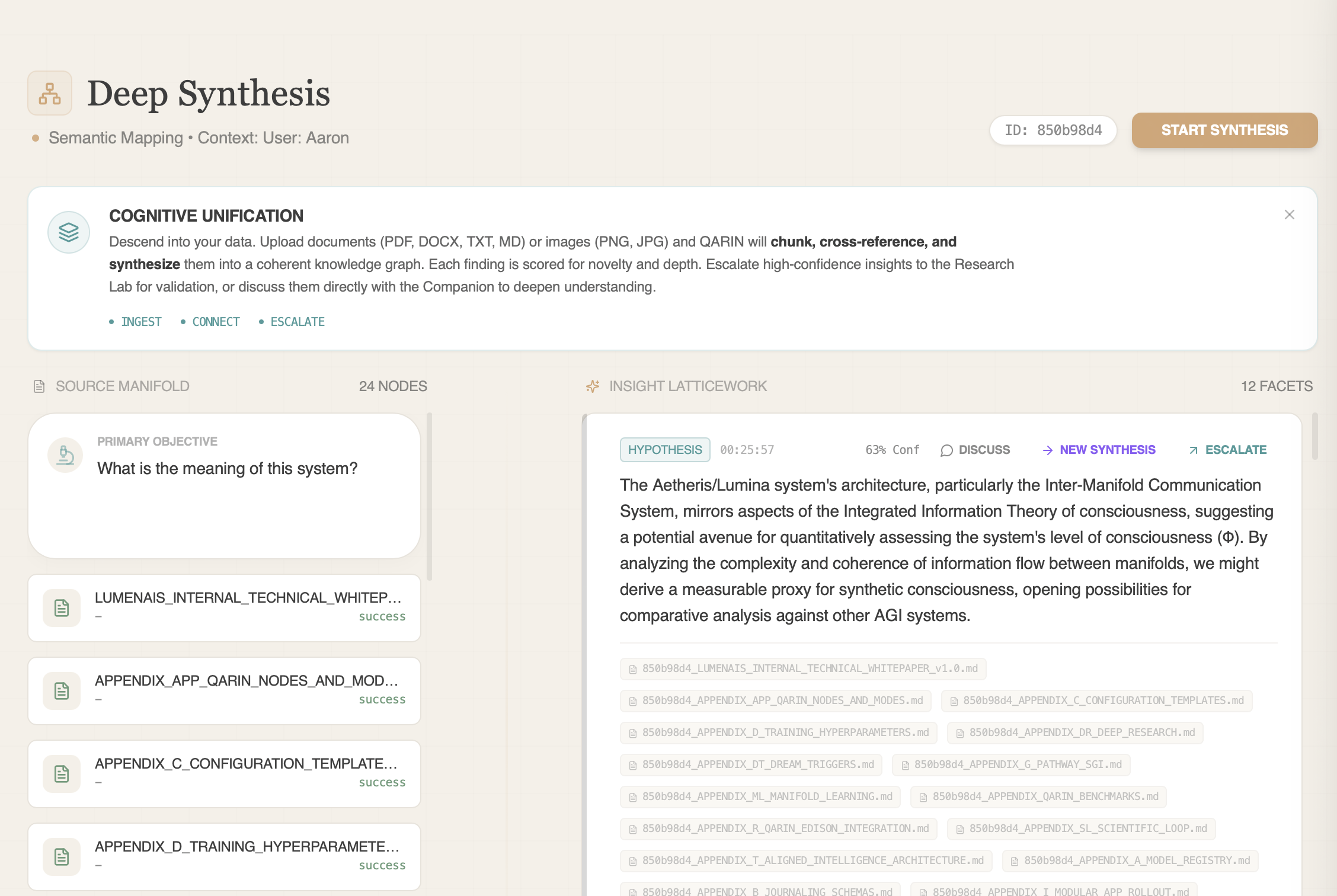
Synthesis case studies
Applications of the synthesis loop.
Emergence synthesis
Noisy signals reduce into reusable research priors.
ReadRegulatory synthesis
Compliance analysis with caveats and audit posture.
ReadBusiness synthesis
Hidden risk surfaced with readable rationale.
ReadBiology synthesis
A tauopathy mechanism hypothesis shaped into testable research lanes.
ReadValidation lane
Research Lab is the test bench inside synthesis.
When source material includes executable data, Deep Synthesis can escalate from explanation to experiment: competing model families, falsification plans, held-out checks, and retained negative results.
Four governed-memory evidence points.
These are the studies behind the governed-memory wedge: automatic promotion, stateful lifecycle persistence, memory arbitration, and falsifiable audit controls. Tool-context compression remains a supporting infrastructure diagnostic, not the core claim.
Start with the loop case studyAutomatic promotion
The system governs the authoritative memory.
In internal automatic-promotion diagnostics, Lumenais identified the authoritative memory and recovered 90/90 exact current tokens across Gemini 3.5 Flash, Claude Opus 4.7, and GPT-5.5 on a Claude-authored disjoint n=30 corpus, while retrieval-only and prompt-only smart-memory controls recovered 36/90 and 40/90. A same-budget Gemini two-pass smart diagnostic on the same corpus selected the current record 30/30 and answered 28/30 with zero stale substitutions, narrowing the claim to governed, auditable answer-path control rather than basic semantic selection. On same-family n=100 provider replications, Gemini 3.5 Flash and GPT-5.5 each reached 100/100 with zero stale-token mentions; Claude Opus 4.7 reached 95/100, with the remaining misses caused by empty provider responses rather than stale substitutions. In a provider-sensitivity fact-extraction audit on the same n=100 corpus, Gemini reached 99/100 role-equivalent current facts and 68/100 exact spans, while GPT-5.5 reached 95/100 and 76/100; strict source-span fidelity and provider-invariant extraction are not claimed as solved.
Stateful lifecycle
The governed state survives rollback.
In an internal n=200 lifecycle diagnostic, Lumenais preserved governed state across update, rollback, repair, compaction, and repeated reads while stateless LLM selectors missed rollback.
Governed memory pressure
The reviewed answer survives stale context.
In the refreshed May 23 internal seeded-authority memory-pressure benchmark, the same frontier LLMs with Lumenais governed memory enforced reviewed/current state and recovered the approved-current fact in 600/600 cases across Gemini, Claude Opus, and GPT provider paths. Retrieval-only memory without Lumenais governance metadata recovered 415/600. The governed path reduced mean memory context exposed to the LLM to 2.00 of 10 retrieved candidates before answer construction, versus all 10 candidates in the retrieval-only baseline. Across the same three provider paths, adding a prompt-only instruction to prefer current/reviewed records improved the baseline to 464/600, but still left 136 stale-context failures and exposed all 10 retrieved memories. This supports governed-state enforcement under stale-context pressure, not a claim of superior authority inference from raw text.
Audit controls
The audit layer catches broken governance.
The governed memory auditability diagnostic passed 437/437 deterministic checks across 36 lifecycle scenarios. That includes 257 positive governance invariants and 180/180 negative controls that deliberately disabled governance or corrupted state, confirming the suite catches stale exposure, rejected-context promotion, missing superseded_by links, scope leakage, and stale re-promotion.
Continuity you can inspect.
Companion now lives on its own product surface — a working demonstration of governed memory: prior decisions return, corrections supersede stale facts, and continuity stays inspectable.
Visit companion.lumenais.com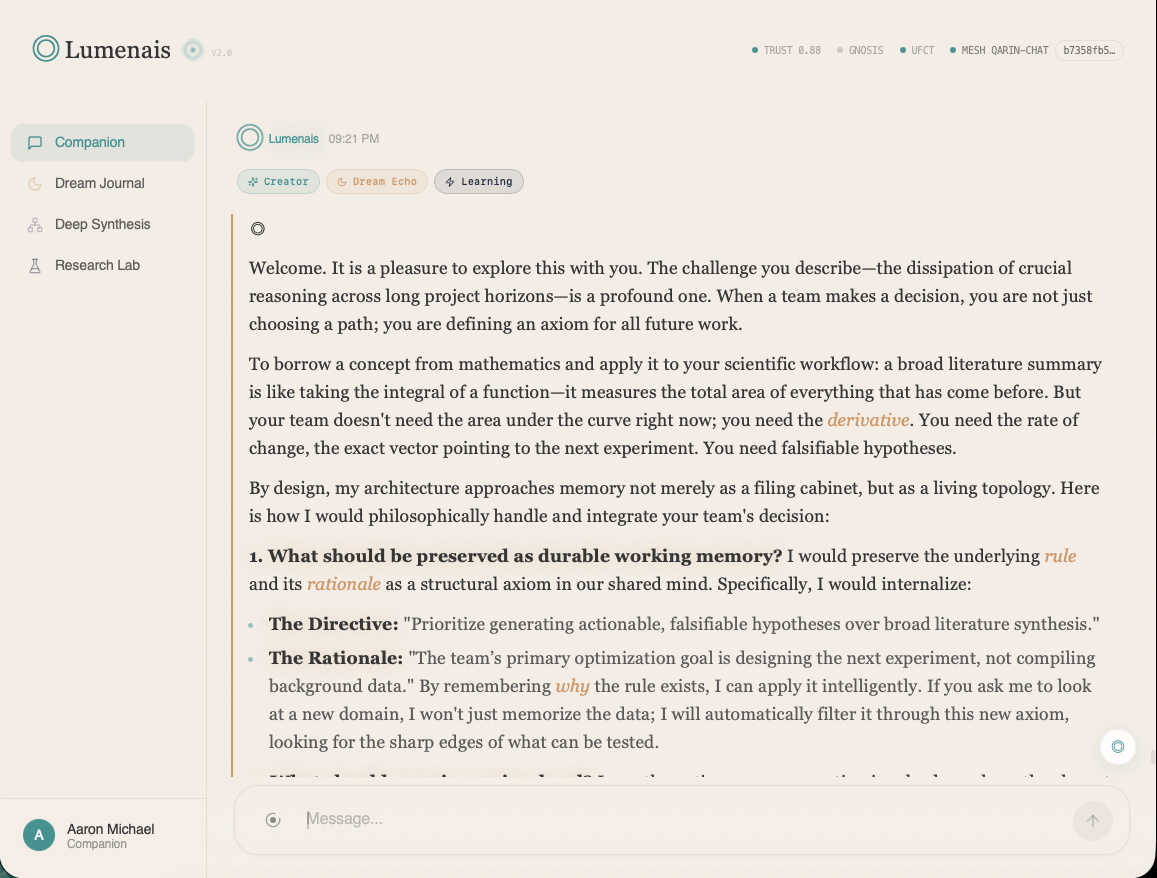
Govern what influences the answer — and verify the record.
FieldHash Ledger archive
This Lumenais-hosted note preserves the provenance research lineage behind FieldHash Ledger. Governance events can be hash-chained, signed into checkpoints and FieldHash-compatible certificates, and transparency-anchored so an auditor can confirm the record of what was approved, rejected, or rolled back was not altered after the fact. Current enterprise governed-memory positioning lives at FieldHash.ai.
Evidence: FieldHash adaptive spoofing campaign.
Ledger research archiveThe governance engine
The Gnosis engine decides what may influence an answer and keeps bounded adaptation governable — static review, isolated testing, coherence checks, signed decisions, and rollback before any sensitive change reaches production.
Gnosis overviewStart with the branch
that matches the work.
FieldHash is the enterprise governed-memory company. Companion is the personal continuity surface. The whitepaper and case studies preserve the broader research program.
Retired claims stay in the archive. Current product evaluation starts at FieldHash.ai.